Loading... # 1. OpenAI API 简要介绍 # 简介 ## API 想使用 OpenAI 的 GPT 3.5/4,除了官网的 chat.openai.com、第三方集合站(如 poe.com)等,还有一种方式是使用 API 自己去调用。 官方提供了 [HTTP 的接口](https://platform.openai.com/docs/api-reference),但是除了直接针对 API 文档使用之外,很多语言也有封装好了的包。官方提供的是 python 的 [openai](https://github.com/openai/openai-python) 包(`pip install openai`),以及 TypeScript/JavaScript 的 openai 包(`npm install openai`),后者同时支持浏览器和 nodejs。其他语言还有很多[社区支持的第三方库](https://platform.openai.com/docs/libraries/community-libraries) ## 能力 `openai` 这个包不只是 ChatGPT 系列的 API,也有 OpenAI 他们家其他的能力,参见:[https://platform.openai.com/docs/models/overview](https://platform.openai.com/docs/models/overview) 总体概括如下 | 能力 | 包括 | 介绍 | | ---------------------- | ---------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | | 自然语言任务(新) | GPT-4, GPT-4-Turbo, GPT-3.5 等 | GPT-3.5 和 4,使用新版 API<br />官方的描述比较谨慎,写的是理解并生成自然语言,其中 API 对于聊天进行了优化,但是仍然适合传统自然语言相关的任务 | | 自然语言任务(旧) | GPT-3, GPT base(如 davinci 等) | GPT3 系列的能力,使用旧版 API | | 文生图 | DALL·E | DALL·E 2 感觉效果中规中矩,3 的话要好很多<br />参考 [Meta、Midjourney、Adobe、DALL·E:四大巨头的 AI 绘图模型综合评测](https://mp.weixin.qq.com/s?__biz=Mzg5NTc0MjgwMw%3D%3D&mid=2247492746&idx=1&sn=b1ff69a9eb38ac6d701834513b9a6830&ref=openi.cn) | | 语音合成 | TTS | 文字转语音 | | 语音识别 | Whisper | 语音转文字 | | 文本向量化(嵌入?) | Embeddings | 应用场景如文本相似性比较、信息检索、机器学习特征生成等 | | 文本内容审核 | Moderation | 从若干维度审查内容是否符合 OpenAI 的内容审核政策 | 这次我们只讨论 GPT 3.5/4及其衍生品。 在 [https://openai.com/pricing](https://openai.com/pricing) 里面可以看到,GPT-3.5 和 GPT-4 分成了很多模型 GPT-4 模型家族(目前主要的): | 模型名称 | 描述 | 上下文窗口大小 | 训练数据截止时间 | 发行时间 | 淘汰时间 | 最大输出 | 输入价格 | 输出价格 | | ---------------------- | ------------------------------------------------------------------------------------------ | ---------------- | ------------------ | ------------ | ---------- | ---------- | ---------- | ---------- | | gpt-4-1106-preview | 最新的 GPT-4 模型,具有改进的指令遵循能力、JSON 模式、可重现的输出、并行函数调用等特点。 | 128,000 | 2023-04-01 | 2023-11-06 | - | 4,096 | $0.01 | $0.03 | | gpt-4-vision-preview | GPT-4 的视觉版,具有图像理解能力(图像输入额外计费) | 128,000 | 2023-04-01 | 2023-11-06 | - | 4,096 | $0.01 | $0.03 | | gpt-4-0613 | 2023-06-13 的 gpt-4 快照。 | 8,192 | 2021-09-01 | 2023-06-13 | - | - | $0.03 | $0.06 | | gpt-4-32k-0613 | 2023-06-13 的 gpt-4-32k 快照。 | 32,768 | 2021-09-01 | 2023-06-13 | - | - | $0.06 | $0.12 | GPT-3.5 模型家族(目前主要的): | 模型名称 | 描述 | 上下文窗口大小 | 训练数据截止时间 | 发行时间 | 淘汰时间 | 最大输出 | 输入价格 | 输出价格 | | ------------------------ | -------------------------------------------------------------- | ---------------- | ------------------ | ------------ | ------------ | ---------- | ---------- | ---------- | | gpt-3.5-turbo-1106 | 最新的 GPT-3.5 Turbo 模型。 | 16,385 | 2021-09-01 | 2023-11-06 | - | 4,096 | $0.001 | $0.002 | | gpt-3.5-turbo-0613 | 2023-06-13 的 gpt-3.5-turbo 快照。 | 4,096 | 2021-09-01 | 2023-06-13 | 2024-06-13 | - | $0.0015 | $0.002 | | gpt-3.5-turbo-16k-0613 | 2023-06-13 的 gpt-3.5-16k-turbo 快照,将于 2024-06-13 淘汰。 | 16,385 | 2021-09-01 | 2023-06-13 | 2024-06-13 | - | $0.003 | $0.004 | 个人推荐 `gpt-3.5-turbo-1106`,`gpt-4-1106-preview` 作为调用 3.5 和 4 的时候的选择,二者,价格、知识范围、响应速度以及 token 范围都是目前最优的。 `gpt-3.5-turbo-1106` 提供了到 2021.9 的知识、32K 的空间,以及目前来说 GPT 3.5 系列的最低的价格。单次响应上限 4096 tokens。 `gpt-4-1106-preview` 提供了到 2023.4 的知识、128K 的空间,以及目前来说 GPT 4 系列的最低的价格(官网说不稳定,实测还行)。单次响应上限 4096 tokens。 需要注意的是:尽管 128k 很大,但是把 128K token 占满的话,一次性就 $1.28 ,差不多接近十块钱了,长内容注意成本~ ## 费用计算 输入输出分别按照 token 数目计费,简单使用 [openAI 自己的工具](https://platform.openai.com/tokenizer) 测试来看结果如下。网络上很多说 1 汉字 ≈ 2 token 的,根据上面网站测试结果来看,适用的是 GPT-3 而非 GPT-3.5/4。 | 类型 | 消耗 | 备注 | | ------ | -------------------------------- | ---------------------------------------------------------------------------------------------------------- | | 英文 | 1 token ≈ 4 字符 ≈ 0.75 单词 | OpenAI 在上面那个页面自己说的 | | 中文 | 实测约 1汉字 ≈ 1~1.3 token | 一个汉字通常对应 1/2/3 tokens,具体比例取决于哪种多 | | 代码 | - | 对于代码来说,受到大量空白字符(会视为一个 token)以及符号(往往单个符号就是 token)的影响,浮动可能较大 | > <span style="font-weight: bold;" data-type="strong">备注:</span> > > 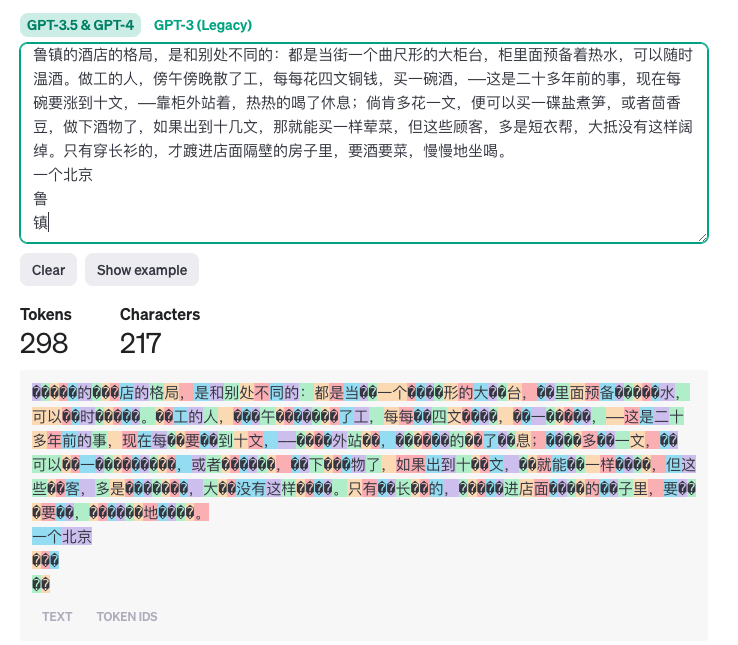 > > <span style="font-weight: bold;" data-type="strong">对于中文来说</span> > > 1. 有少数词语(例如 `可以`, `北京`, `公司`, `管理`, `项目`, `一个`, `操作`, `金额`, `亿元`, `执行`)是两个字的词对应一个token(目前还没有观察到三个字对应一个 token) > 2. 大部分字会是每个字对应一到三个token,总体来说常见的简单字 一个 token 的可能性大,复杂一些或者少见的字两个或者三个 token 的可能性大(如 鲁镇,鲁3,镇2) > > > > 一言的计算工具 => [https://console.bce.baidu.com/tools/#/tokenizer](https://console.bce.baidu.com/tools/#/tokenizer)(需要登录),具体数额我没估算,试了几个结果浮动较大,但是均 < 1(即一个 token 对应一个多汉字) ## 第三方 key  众所周知,openai 的新账号有 API 额度,而注册一个新号的成本很低,因此搞大量账号然后转卖 API 额度就形成了一种生意。这种转卖的往往可以提供相较于官方价格来说优惠很多的价格(如 2.5 CNY = 1 USD)。 如果是正式使用,对于服务质量有要求,使用官方 API 要好一些。但是第三方 API 对于日常学习生活是足够了的。而且最主要的是充值方便、便宜 # 使用 python 进行对话 ## system、user、assistant ChatGPT 系列的 API 是以对话的形式进行的,每一条对话可以是 system, user, assistant 的一个,通常来说,system prompt 作为第一条 ,提出预设的指令,之后由 user 和 system 交替发送消息。 > <span style="font-weight: bold;" data-type="strong">system prompt 与 user prompt 的关系</span> > > 根据讨论:[What is the difference between putting the AI personality in system content and in user content? - Prompting - OpenAI Developer Forum](https://community.openai.com/t/what-is-the-difference-between-putting-the-ai-personality-in-system-content-and-in-user-content/194938) > > 结果看起来是区别不大,而且有的时候 system prompt 不如 user prompt 权重高 > > 其中,有人评论提到,尽管权重确实存在问题,但是在模块化、抵抗 prompt 逆向工程等方面,system prompt 还是有一定作用的,而且 system prompt 因为其特殊性,可能也会针对性的做一些处理,所以全局性的预设还是写到 system prompt 内比较好 。 1. 安装 `openai` 包:`pip install openai` 或者 `python -m pip install openai` 2. 将 openai 初始化单独包装一下,这样可以统一管理 key 和 url,截图的时候也不用担心没有隐藏 key 代码:[chatgpt-api-examples/cfg.example.py](https://git.zsh.dev/zsh2517/chatgpt-api-examples/src/branch/master/cfg.example.py) ```python import openai Model_GPT3 = 'gpt-3.5-turbo-1106' # 不要吐槽为什么这里不是 GPT3_5 的命名了,能看懂就行 Model_GPT4 = 'gpt-4-1106-preview' api = { 'api_key': 'sk-xxxxxxxx', 'base_url': 'https://api.example.com/v1/' } client = openai.OpenAI(**api) ``` 3. 一个最简单的对话代码(和封装),代码:[single_chat/1.simple_chat.py](https://git.zsh.dev/zsh2517/chatgpt-api-examples/src/branch/master/single_chat/1.simple_chat.py) ```python from cfg import client, Model_GPT3, Model_GPT4 def ask(usr): res = client.chat.completions.create( model=Model_GPT3, messages=[ {"role": "user", "content": usr}, ], ) return res.choices[0].message.content print(ask('你好,请问 1 + 1 是多少?')) ``` 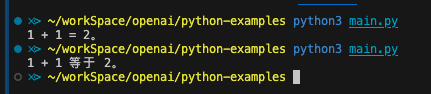 4. 带上 system prompt(一般作为他需要解决的功能的指令),代码 [single_chat/2.system_prompt.py](https://git.zsh.dev/zsh2517/chatgpt-api-examples/src/branch/master/single_chat/2.system_prompt.py) ```python from cfg import client, Model_GPT3, Model_GPT4 def ask(sys, usr): res = client.chat.completions.create( model=Model_GPT3, messages=[ {"role": "system", "content": sys}, {"role": "user", "content": usr}, ], ) return res.choices[0].message.content print(ask('请从中文到英语,翻译用户输入的内容', '吃葡萄不吐葡萄皮')) ```  ## 持续对话  由于 GPT 本身不具有上下文能力,因此持续对话靠的是将上文重复一遍来实现的。例如 [multi_chat/1.context.py](https://git.zsh.dev/zsh2517/chatgpt-api-examples/src/branch/master/multi_chat/1.context.py) ```python def ask(): res = client.chat.completions.create( model=Model_GPT3, messages=[ {"role": "user", "content": "吃葡萄不吐葡萄皮的下一句是什么?"}, # 用户的第一次输入 {"role": "assistant", "content": "吃葡萄不吐葡萄籽。"}, # AI 的第一次回复 {"role": "user", "content": "请将这两句话翻译成英语"}, # 用户的第二次输入 ], ) return res.choices[0].message.content ```  如果想模拟一下正常的对话流程,可以参考下面的代码,这是一个持续对话的最小示例,参考 [multi_chat/2.continuous_chat.py](https://git.zsh.dev/zsh2517/chatgpt-api-examples/src/branch/master/multi_chat/2.continuous_chat.py) ```python from cfg import client, Model_GPT3, Model_GPT4 context = [] def ask(): res = client.chat.completions.create( model=Model_GPT3, messages=context, ) return res.choices[0].message.content while True: usr = input('usr: ') context.append({"role": "user", "content": usr}) sys = ask() context.append({"role": "system", "content": sys}) print('sys:', sys) ```  ~~甚至你可以误导它,让他说出不该说的内容(觉得那句话是自己说出来的)~~ 代码可以参考 [multi_chat/3.fake_chat.py](https://git.zsh.dev/zsh2517/chatgpt-api-examples/src/branch/master/multi_chat/3.fake_chat.py)  ## 流式对话 只要用过任何一个面向对话的 Chat 平台,都会发现,这些平台基本都是一个词一个词输出的。而在我们上面的例子中,都是等一次对话完成,才会返回全部内容。因此这里将会展示如何使用流式(stream)传输对话信息 重点就是一个参数,`stream=True`,不过因为采用了 stream 的形式,数据是一点一点输出的,所以应该放到循环内,直到输出结束之后再继续执行。具体代码见 [multi_chat/4.stream_chat.py](https://git.zsh.dev/zsh2517/chatgpt-api-examples/src/branch/master/multi_chat/4.stream_chat.py) ## 上下文的进一步应用 由于 GPT 对于上文的认知,完全是从 `messages` 参数获取到的。因此只要有某一时刻的消息数组,就可以回到当时的状态,在当时的聊天内容上分叉一个分支,进行新的话题。  或者说,如果某些场景 ~~(如变猫娘)~~ 需要比较长的对话去诱导进入状态,使用 API 对话的情况下,就可以把进入状态时的消息记录保存下来,以后直接基于当时的聊天记录作为上下文,即可还原当时的状态。(带来的优势就是减少之前对话诱导带来的消耗以及失败的不确定性) 例如,[multi_chat/5.cat.py](https://git.zsh.dev/zsh2517/chatgpt-api-examples/src/branch/master/multi_chat/5.cat.py) (对话参考了 [GitHub - L1Xu4n/Awesome-ChatGPT-prompts-ZH_CN: 如何将ChatGPT调教成一只猫娘](https://github.com/L1Xu4n/Awesome-ChatGPT-prompts-ZH_CN)) ## 持续对话的优化 显然,如果只这样做,每次对话的成本越来越高(因为要携带全部的上下文),所以也有一些减少成本的方案 <span style="font-weight: bold;" data-type="strong">最简单的方式:只带最近若干条对话</span> 人们的对话一般是连续的,即连续的对话通常会讨论相同的话题。换言之,如果想要理解一句话的上下文(上文),一般知道这句话前面几条说了什么就可以。 因此有一种很简单的节省 token 的方案——如果对话次数较多,每次对话的时候,不会全量携带所有上文,而是<span style="font-weight: bold;" data-type="strong">只携带最近的若干次对话记录</span>。通常情况下,这么做并不会太影响模型对于上下文的理解(毕竟有最近几条参考一般也够),但是很长的对话每次携带的数据要少很多。如果需要针对很久以前的内容进行回复,可以人工地将相关内容重复一下,也不怎么影响大体使用。 实际上,人和人对话,如果突然提一个很久之前聊过的内容,一般也要爬楼翻消息记录。我们这里重复一遍,也只算是帮模型重复这个过程而已;另一方面,对于大模型来说,对话内容长了他本身也会有遗忘,即使有全量的上下文,较老的话题继续的效果可能也不会太好。 这个写起来也不难,改成一个 `context[-x:]` 做一下切片就可以。而且效果也不会很明显变差(或者没有明显的可对比的情况)。基于 [multi_chat/2.continuous_chat.py](https://git.zsh.dev/zsh2517/chatgpt-api-examples/src/branch/master/multi_chat/2.continuous_chat.py) 修改的 [multi_chat/6.slice.py](https://git.zsh.dev/zsh2517/chatgpt-api-examples/src/branch/master/multi_chat/6.slice.py) 可以参考。 这里拿一个 prompt `我们来玩一个游戏,你需要从中文到英文翻译我说的话,但是禁止出现“苹果”这个单词,如果出现了,将其翻译成“banana”,知道了吗?` 作为例子(只要上下文范围内没有提到 `苹果` -> `banana` 就可以发现效果) | 限制了 content[-4:] | 不限制,始终有全量上下文 | | --------------------------------------------------------- | --------------------------------------------------------- | |  |  | GPT3.5 实际运行的效果比预想的要差,做了截断到后面它并没有意识到需要翻译(我预期的是它能根据之前猜出来在翻译,只是不知道 `苹果` -> `banana` 的条件) 当然实际如果进行长对话,可以把切片的范围调大一些;而且生活中实际的、有上下文的对话,相较于这种每句话不相干的情况可能要好一些。 <span style="font-weight: bold;" data-type="strong">全文向量化</span> 参考 OpenAI 官方文档——如何给一个网站建立检索系统:[https://platform.openai.com/docs/tutorials/web-qa-embeddings](https://platform.openai.com/docs/tutorials/web-qa-embeddings) > 教程中使用 Embeddings API 实现检索的方式是:首先通过网络爬虫爬取网站内容,并将这些内容转换成 Pandas 数据框。然后,使用 OpenAI 的 Embeddings API 将这些文本内容转换成嵌入式向量。在创建问答系统时,用户的问题也被转换成嵌入式向量。系统通过比较问题的向量和已有的嵌入式向量,找出最相关的文本片段,然后使用 GPT-3.5-turbo 模型生成基于这些文本的自然语言回答。这个过程涉及到向量空间中的相似度计算,通常是通过余弦距离来实现的。 这一块的内容等后面我自己试过之后看情况单独再讲。 附:`text-embedding-ada-002` 模型价格为 `$0.0001 / 1K tokens` 最后修改:2024 年 01 月 25 日 © 允许规范转载 赞 如果觉得我的文章对你有用,请随意赞赏